Overzicht
In 2019 en 2020 deed Fileradar, samen met Deltares, prototype-onderzoek naar de toepasbaarheid van Artificial Intelligence in het domein van het voorspellen van verkeer en rivierwaterstanden. Met het onderzoek hebben we aangetoond dat het ontwikkelen van AI-modellen die gebaseerd zijn op ‘echte’ modellen haalbaar is en kan leiden tot verbeterde voorspellingen.
De lessen uit dit project zijn toepasbaar op zowel watermodellen als verkeersmodellen, aangezien de modellen voor verkeer en voor waterstromen veel overeenkomsten vertonen. Het onderzoek is gefinancierd door RVO.
Aanpak
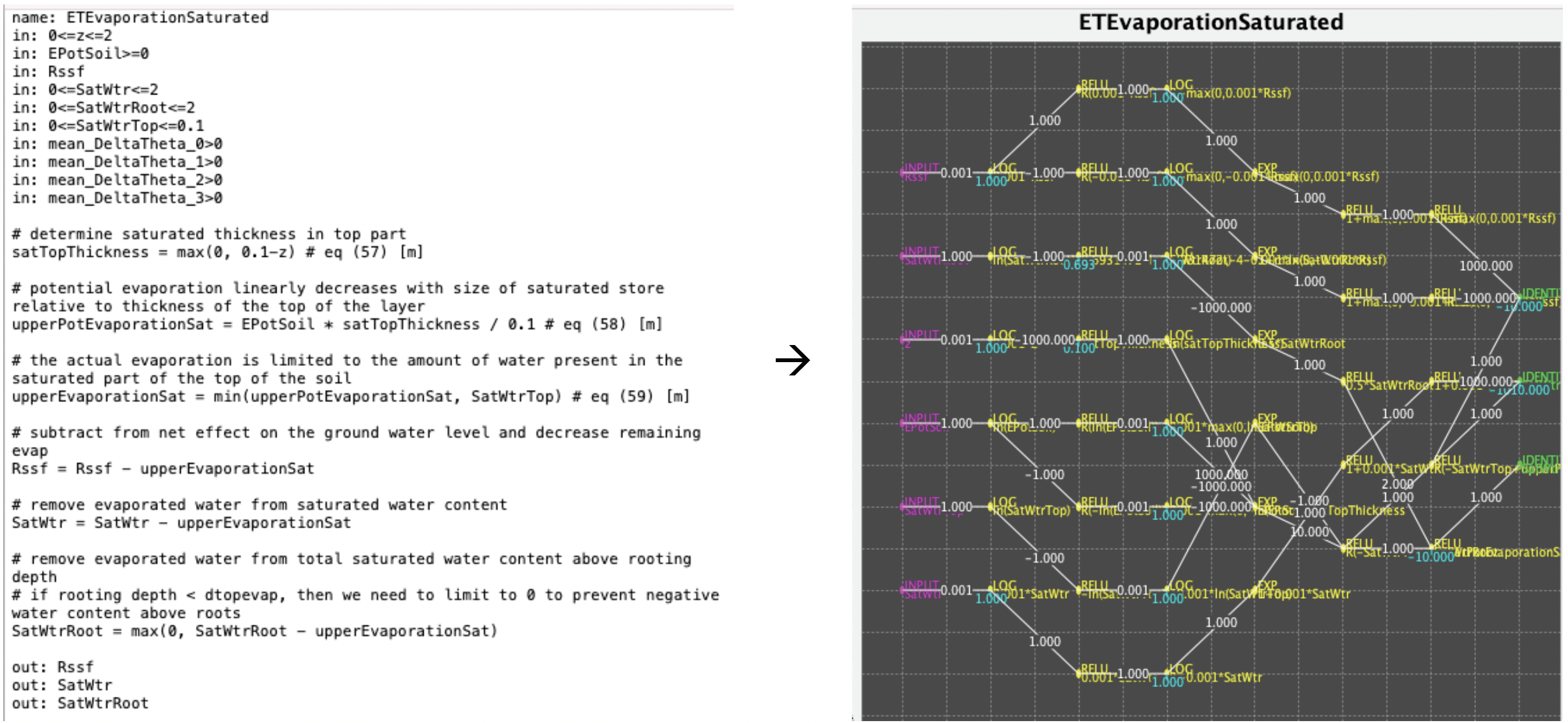
In de laatste jaren neemt de inzet van Artificial Intelligence een enorme vlucht. Recente doorbraken in tekstgeneratie, beeldherkenning en zelfs domeinen als muziek en video leiden al snel tot de vraag of AI ook geschikt zou kunnen zijn voor de verbetering van modellen voor water- en verkeersstromen. Fileradar heeft een concept ontwikkeld waarin ‘white box’ modellen omgezet worden naar ‘black box’ modellen. Iedere formule uit het te gebruiken model wordt omgezet in een neuraal netwerk. Hiervoor heeft Fileradar een compiler ontwikkeld, die dat geautomatiseerd kan doen. Verschillende neurale netwerken worden vervolgens achter elkaar geplaatst, waarna een keten van neurale netwerken ontstaat.
Deze keten van neurale netwerken kan vervolgens worden getraind om zijn voorspellingen te verbeteren. Omdat de neurale netwerken zijn gebaseerd op een ‘echt’ model, zijn de eerste voorspellingen al heel redelijk. Gaandeweg het trainen wordt het model steeds beter, en wijkt het stap voor stap steeds meer af van de oorspronkelijke formules.
Resultaten
Experimenten met het Lighthill Whitham Richards (LWR) verkeersmodel op echte verkeersnetwerken laten zien dat deze aanpak kan leiden tot tientallen procenten verbetering.
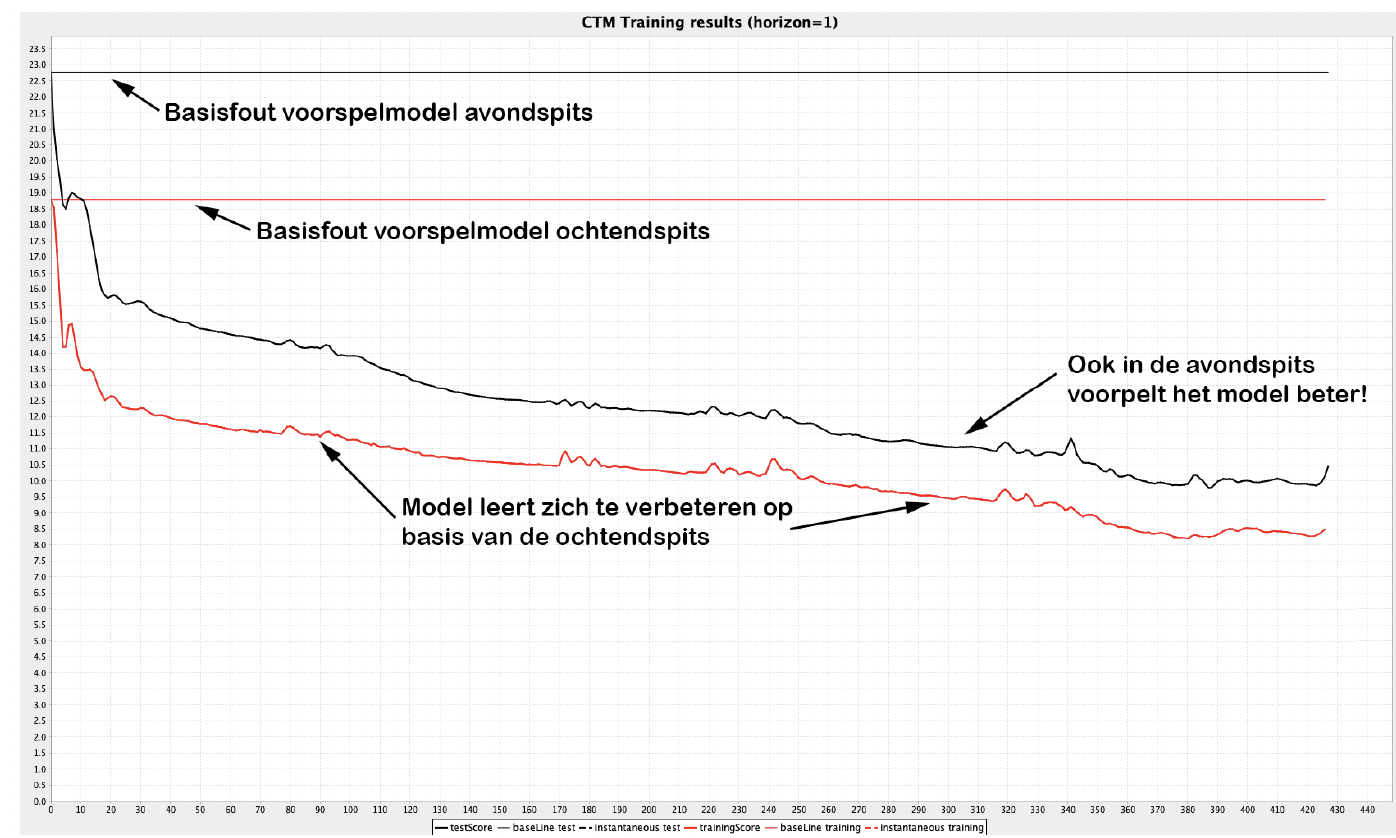
Onderstaande grafiek toont de resultaten van een experiment, waarin een verkeersmodel in een ochtendspits is getraind op alle snelwegen rond Rotterdam. De rode horizontale lijn toont de originele fout van het ‘white box model’. De dalende rode lijn toont aan dat het model steeds betere voorspellingen gaat maken als we het zichzelf laten verbeteren; de fout daalt met 58%. Nog belangrijker is dat wanneer het verbeterde model vervolgens in de avondspits wordt toegepast, het ook dan betere voorspellingen maakt (de zwarte lijn), de fout daalt daar met 56%. De verbetering is dus structureel, en werkt niet alleen op de data die gebruikt is om het model te trainen.
Een tweede belangrijk resultaat: het geleerde is verplaatsbaar. Wanneer het in Rotterdam getrainde model wordt toegepast in Utrecht, blijkt dat het óók daar beter voorspelt. De fouten in de ochtendspits en avondspits op een volledig ander netwerk dalen met respectievelijk 30% en 43%.
Resultaten van de toepassing op het voorspellen van rivierwaterstanden zijn er nog niet. Hiervoor moet nog een aantal stappen worden gezet, waarvoor in de toekomst mogelijk ruimte komt.