Betere monitoring van luchtkwaliteit met data
In het najaar van 2024 heeft Fileradar een pilot georganiseerd om samen met overheden die deelnemen aan het Schone Lucht Akkoord te zorgen voor betere monitoring van de luchtkwaliteit met het CIMLK. Na een flinke zoektocht hebben we 9 verschillende databronnen gevonden waarmee je de monitoring in CIMLK een stuk beter kunt maken. In diverse online sessies hebben we al deze databronnen samen met alle deelnemende overheden één voor één doorlopen.
De pilot heeft laten zien dat de monitoring daarmee nauwkeuriger en completer wordt. Daarmee ontstaat een tool waarmee je ook maatregelen voor betere luchtkwaliteit door kunt rekenen.
Aan de pilot namen 24 gemeenten, provincies en omgevingsdiensten deel. Zij hebben zeer waardevolle feedback gegeven op de hele methodiek om datagedreven de CIMLK-bestanden samen te stellen. Door middel van discussies in ons online portaal en in de online meetings zijn we veel wijzer geworden, en hebben we de procedures voor het genereren van CIMLK-invoerbestanden naar een hoog niveau kunnen tillen.
Over dit onderwerp hebben we ook een webinar georganiseerd. Je kunt deze webinar hier terugkijken.

Veel nauwkeuriger monitoring
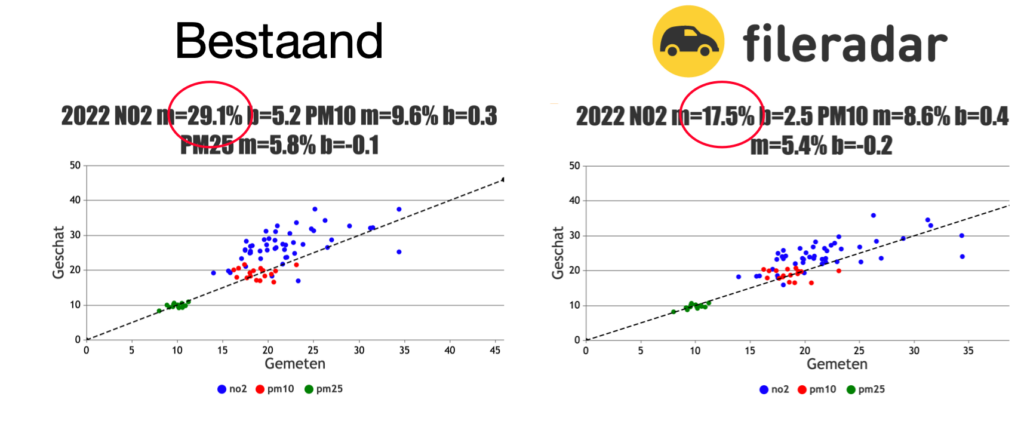
Het resultaat van alle inspanningen is heel duidelijk: de monitoring met de input zoals gegenereerd door Fileradar is veel nauwkeuriger dan met wat er tot nu toe gedaan wordt. Onderstaande twee grafieken maken dat duidelijk. We hebben de rekenresultaten uit CIMLK vergeleken met metingen van het RIVM luchtmeetnet voor zowel NO2, PM10 als PM2,5 over 2022. De linkergrafiek toont de resultaten uit CIMLK, met de invoer van gemeenten en provincies zoals ze het nu aanpakken. De rechtergrafiek toont de resultaten met de invoer zoals we die in de pilot hebben vastgesteld. Met name de fout in NO2 daalt veel: van 29,1% naar 17,5%. Ook de monitoring van PM10 en PM2,5 wordt nauwkeuriger. We hebben ook monitoringsjaar 2023 doorgerekend. Daaruit komt dat de fout met Fileradar’s input nog lager is: 13,9% voor NO2. Blijkbaar was 2022 een ‘moeilijk jaar’ om door te rekenen.
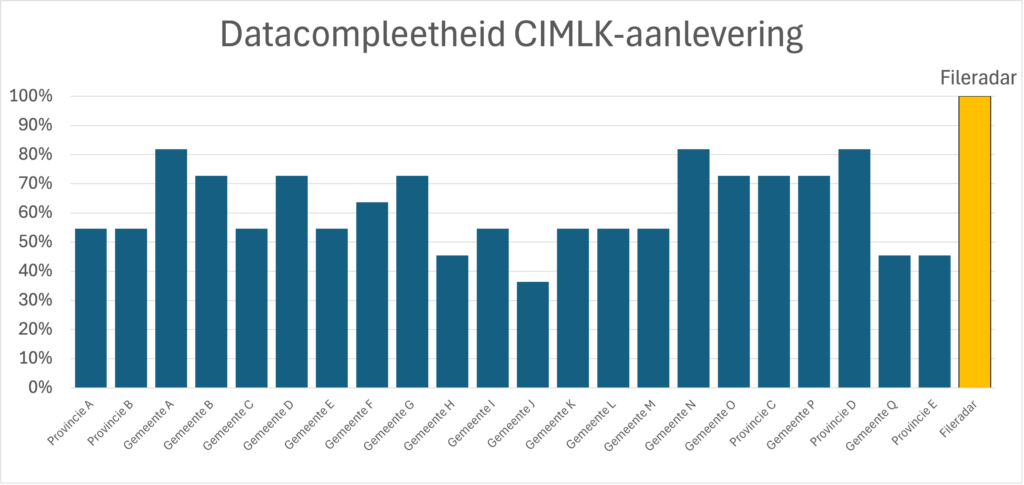
Van 62% naar 100% datacompleetheid
Tijdens de pilot hebben we ook gekeken naar hoeveel van de invoervelden wordt ingevuld door gemeenten en provincies die gegevens aanleveren. We hebben hiervoor 155 uploads geanalyseerd die door gemeenten, provincies en omgevingsdiensten zijn aangeleverd. Uit deze steekproef blijkt dat geen enkele overheid het lukt om alle velden überhaupt in te vullen. Gemiddeld is maar 62% van de velden ingevuld. Welke velden wel of niet zijn ingevuld verschilt per overheid – de ene heeft alle bomenfactoren op 1 staan, de ander heeft alle stagnatiefactoren op 0 ingesteld, weer een andere heeft alle busintensiteiten op 0 ingevuld, enzovoorts. Uit de pilot blijkt dat het wel degelijk mogelijk is om 100% van de velden in te vullen met landelijk dekkende data en goed doordachte automatisering.
21 invoervelden
In een CIMLK-invoerbestand moet je allerlei verschillende gegevens invullen over het wegennet zelf, het verkeer en de omgeving rondom het wegennet. Het gaat om de volgende 21 invoervelden:
- Bebouwingtype: de mate waarin gebouwen rondom de receptor dicht op de weg staan
- Bomenfactor: de mate waarin bomen rondom de receptor dicht op elkaar staan en wel of niet over de weg steken
- Emissiefactoren voor bussen: per concessiegebied op basis van de verhouding van gebruikte brandstoftypen
- Geluidsschermen- en wallen: of deze links/rechts van de weg staan, inclusief de afstand en de hoogte
- Intensiteit licht verkeer: hoeveelheid personenauto’s en bestelauto’s er gemiddeld per etmaal passeren
- Intensiteit middelzwaar verkeer: hoeveelheid vrachtauto’s <20ton en touringcars er gemiddeld per etmaal passeren
- Intensiteit zwaar verkeer: hoeveelheid vrachtauto’s >20ton en trekker-opleggers er gemiddeld per etmaal passeren
- Intensiteit bussen: hoeveelheid lijnbussen er gemiddeld per etmaal passeren
- Milieu- / ZES-zones: aangepaste emissiefactoren
- Relatieve weghoogte: voor SRM2-wegen hoeveel verhoogd of verdiept de weg ligt
- Snelheidslimiet: de geldende maximum snelheid
- SRM-type: de te gebruiken rekenmethode, SRM1 of SRM2
- Stagnatiefactor licht verkeer: de fractie personenauto’s en bestelauto’s dat gemiddeld per etmaal in file rijdt
- Stagnatiefactor middelzwaar verkeer: de fractie vrachtauto’s <20ton en touringcars dat gemiddeld per etmaal in file rijdt
- Stagnatiefactor zwaar verkeer: de fractie vrachtauto’s >20ton en trekker-opleggers dat gemiddeld per etmaal in file rijdt
- Stagnatiefactor bussen: de fractie lijnbussen dat gemiddeld per etmaal in file rijdt
- Taludsoort: voor SRM2-wegen de vorm van het talud
- Toetssoort: of in de buurt van de receptor mensen verblijven, zodat je daar moet toetsen op normen of niet
- Tunnelfactor: vermenigvuldigingsfactor van emissies ten gevolge van de uitstroom van lucht bij tunnels >100m
- Wegsoort: verdere onderverdeling van SRM-type
- Wettelijke basis: hangt samen met toetssoort
Alles baseren op data
Voor alle invoervelden geldt dat er landelijk dekkende databronnen zijn die je kunt gebruiken om de waarde te bepalen. Dat is vaak niet triviaal. De keuze tussen bijvoorbeeld SRM1 of SRM2 moet je volgens de specificaties baseren op een aantal criteria: in hoeverre er bebouwing is rondom het segment, of de weg verhoogd of verdiept ligt of niet, of er geluidsschermen aanwezig zijn en wat de maximum snelheid is van de weg. Hoe je die afweging precies moet maken is niet gespecificeerd. Deze ‘vaagheid’ in de specificatie bestaat voor veel meer invulvelden. Op basis van multicriteria-analyses hebben we gedurende de pilot deze vage specificaties om kunnen zetten in concrete beslisbomen, die ervoor zorgen dat we elke mogelijke situatie op straat kunnen vertalen naar een concrete keuze voor een waarde van het invulveld.
We gebruiken allerlei verschillende databronnen om de 14 velden in te vullen: Open Street Map, Floating Car Data van NDW, Fileradar’s intensiteiten, 3D BAG, de Algemene Hoogtekaart Nederland (AHN), de BomenMonitor van Cobra, NDOV, enzovoorts. Voor elk van deze bronnen hebben we kritisch gekeken naar de kwaliteit en dekkingsgraad. Op basis daarvan blijkt dat deze bronnen voor veruit het grootste deel van Nederland zeer bruikbaar zijn om geautomatiseerd alle invoervelden voor CIMLK te vullen. De rol van een overheid verandert daarmee van het invullen van gegevens (of het maar leeg laten omdat dat te veel werk is) naar alleen het controleren van automatisch ingevulde gegevens van hoge basiskwaliteit.
Voor elk van de 24 deelnemende gemeenten, provincies en omgevingsdiensten hebben we alle 21 invoervelden uitgedraaid op basis van de landelijk dekkende data en de ontwikkelde algoritmes. De deelnemers hebben vervolgens kritisch gekeken naar de uitkomsten in hun eigen beheergebied. Op het online forum van ons portaal en tijdens een drietal presentaties zijn kritische inhoudelijke discussies gevoerd, waardoor we alle input naar een nog hoger niveau hebben kunnen tillen.
Maatregelen doorrekenen
Gedurende de pilot hebben we ook gekeken naar de mogelijkheden om de CIMLK-rekentool in te zetten voor het doorrekenen van maatregelen. Dit is relevant, omdat de EU nieuwe normen heeft vastgesteld, die vanaf 2030 gaan gelden. Onderdeel van de nieuwe wetgeving is ook dat burgers het recht krijgen schadeclaims in te dienen wanneer de normen worden overschreden. Je wilt daarom de monitoring op orde hebben en waar nodig gericht maatregelen kunnen nemen om de luchtkwaliteit te verbeteren.
We hebben in de pilot laten zien dat je heel goed een Datagedreven Quick Scan uit kunt voeren met alle data en automatisering die we hebben ontwikkeld. Het effect van specifieke maatregelen kun je met behulp van de CIMLK-rekentool omzetten naar het verwachte effect op de levensduur van inwoners van je gemeente of provincie die langs (drukke) wegen wonen. Met grotendeels dezelfde invoer hebben kunnen we ook het effect op het geluid op gevels doorrekenen met ons rekenmodel roadsound. Ook kunnen we in de Quick Scan het effect op het reistijdverlies berekenen. Z

- Met Fileradar-input gemeente Land van Cuijk doorgerekend
- Langs wegen in Boxmeer gaan veel levensjaren verloren
- Wat als we de snelheid verlagen van 50 naar 30?
- De luchtkwaliteit wordt slechter: het kost 3.8 levensjaren
- Het geluid op gevels wordt beter: gemiddeld 3.3 Lden
- De reistijd wordt slechter: +2,8 voertuigverliesuren per dag
360-graden view
Met bovenstaande methodiek is duidelijk dat het mogelijk is om een groot deel van de alle gevolgen van een maatregel in kaart te brengen met slimme data-analyses. Zo kun je een Maatschappelijke Kosten-Baten Analyse uitvoeren. Dit noemen we een 360-graden view: je bekijkt een maatregel van alle kanten.